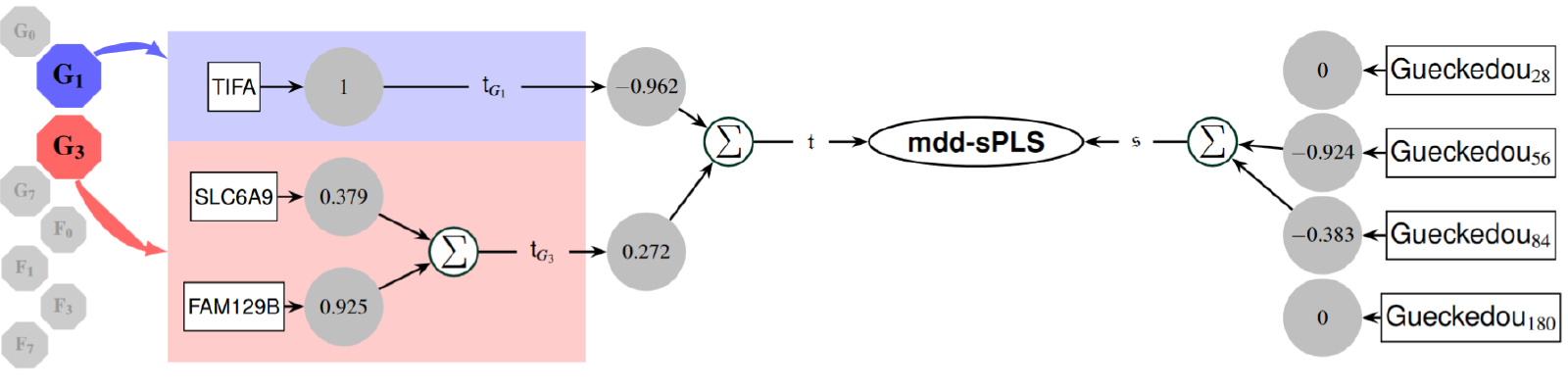
 mdd-sPLS application to the rVSV-ZEBOV dataset
mdd-sPLS application to the rVSV-ZEBOV dataset
A mono/multi-block sparse PLS for heterogeneous data with missing samples
 mdd-sPLS application to the rVSV-ZEBOV dataset
mdd-sPLS application to the rVSV-ZEBOV dataset
A mono/multi-block sparse PLS for heterogeneous data with missing samples
Abstract
This is the last update of the current project on dealing with missing samples in multi-block context for supervised datasets.
Date
Jul 5, 2018
12:00 AM
Event
Séminaire de Biostatistiques
Location
ISPED, Bordeaux, France