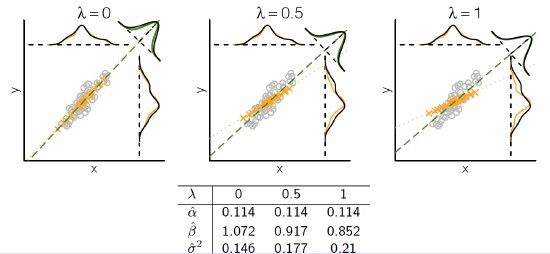
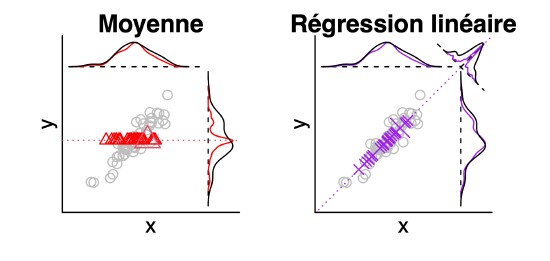
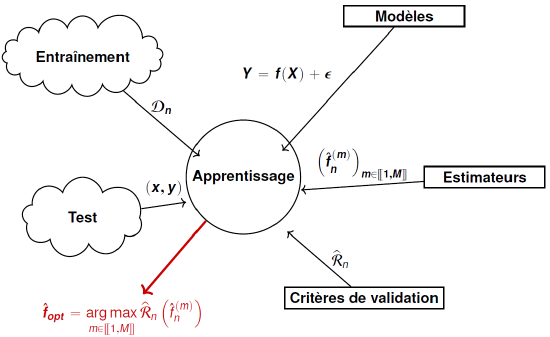
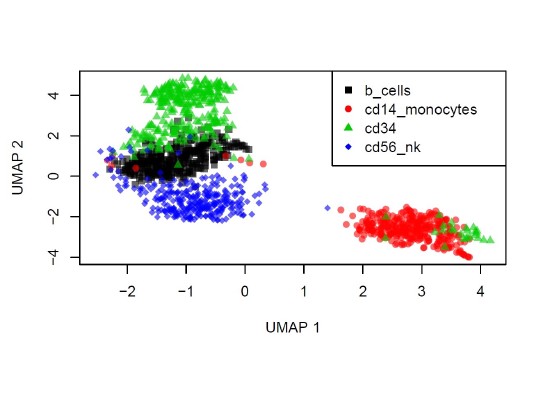
Biography
I am an Associate Professor at Aix-Marseille University (AMU). I teach for all university degrees at the AMU. My reserches are performed in the Statistical group of the ALEA team, one of the teams of the Institut de Mathématiques de Marseille (I2M, UMR 7373).
I currently teach to
- Licence Mathématiques et Informatique Appliquées aux Sciences Humaines et Sociales (MIASHS)
- Master Mathématiques Appliquées, Statistique (MAS)
I2M is an Joint Research Unit (UMR in french) placed under the triple tutelage of the CNRS, AMU and the École Centrale de Marseille.
I unreasonably work on R and you can view the current stage on my packages on GitHub. My wish is to be useful to both of the communities which have so much to share!
Interests
- Statistical modelling
- Missing Value Treatment
- Variable selection
- SIR
- Bootstrap
- Extreme Value Theory
- Bayesian Statistics
- PLS
- Machine Learning
- Teaching
Education
-
PhD in Biostatistics, 2019
Université de Bordeaux
-
Research Master, Applied Mathematics for Image and Signal Processing, 2015
CentraleSupelec and Paris-Sud University