Apprentissage supervisé pour données massives multi-blocs incomplètes
Apprentissage supervisé pour données massives multi-blocs incomplètes
Abstract
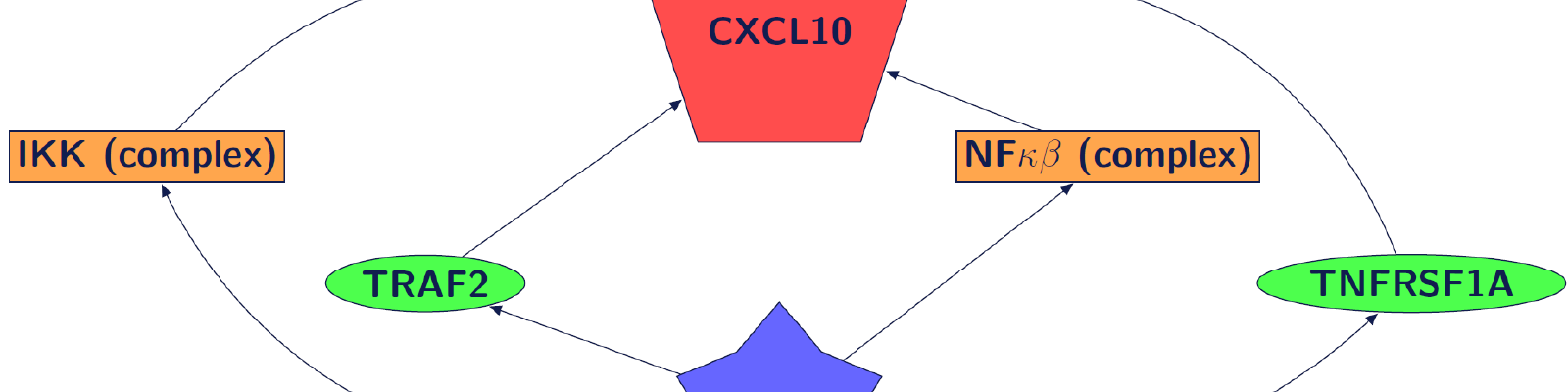
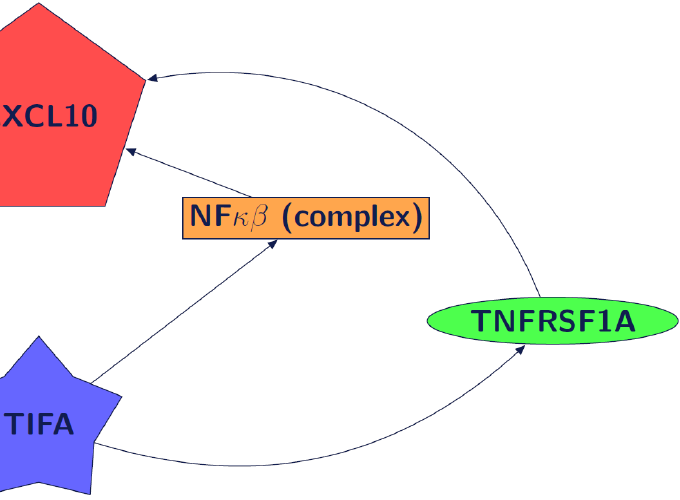
Les récentes innovations techniques ont permis la production de données massives en biologie, comme les données omiques par exemple (génomique, transcriptomique, protéomique, …). Ces données peuvent être manquantes pour des raisons techniques (mauvaise qualité de l’extraction de l’ARN à un temps de prélèvement par exemple). Or, un transcriptome manquant signifie la perte de l’expression de milliers de gènes. Nous avons rencontré ce problème pour l’analyse de données de vaccination Ebola rVSV [5] où plus de 30% de l’information était manquante. Avec ces données de vaccination Ebola, la question est de prédire la réponse anticorps des patients, c’est donc un problème supervisé.
Date
May 16, 2019
12:00 AM
Event
Journée de l’Ecole doctorale EDSP2 2019 - JEDSP2 2019
Location
Bordeaux